NUPLAN CLOSED-LOOP SIMULATION
Stable Inference Latency at 1000-Agent Scale
In continuous closed-loop robotics environments, sequence-mixing architectures face a strict hardware barrier: concatenating historical state for every micro-adjustment causes an $O(N^2)$ compute and memory explosion. We isolated this trap by benchmarking ZetaPhi's bounded-state temporal integration against a Dense Transformer across 1,000 simultaneous agents.
1000-Agent Closed-Loop Trajectory Parity Match
*Evaluated on 1,000 simultaneous agents over 1,000 physics ticks. 500k parameter budget. Both models normalized for relative kinematics.*
| Architecture | Validation MSE | Peak VRAM | Tick 1000 Latency | Safety Standard |
|---|---|---|---|---|
| Dense Transformer | 0.0143 | 4,430 MB | 226.93 ms | Violates 100ms Deadline |
| ZetaPhi Spectrum 64W (Ours) | 0.0137 | 44.6 MB | 0.0095 ms | Continuous Real-Time |
The Conclusion: The Dense Transformer natively hits a latency wall as its Key-Value history grows, causing simulated collisions as it violates the 100ms control deadline. ZetaPhi achieves identical trajectory accuracy while executing natively in 9.5 microseconds via its native fused stateful inference runtime, proving the fundamental requirement of linearly scaling continuous-time architectures for edge robotics.
ROBOMIMIC V1 — CONTINUOUS ROBOTIC CONTROL
Wide geometric topologies natively map to complex multi-actuator telemetry.
The Bottom Line: Learning human teleoperation requires modeling complex dependencies across gripper actuations and joint velocities. The ZetaPhi spatial-temporal policy monotonically scaled down error, achieving a parameter-matched baseline win against the Dense Transformer.
WHAT IT MEANS
Massively parallel temporal tracking.
Unlike simple kinematics, multi-actuator robotics benefits from wide, highly parallel topologies. ZetaPhi spatial-temporal policy successfully tracked isolated temporal frequencies simultaneously, cleanly separating high-frequency jitter from long-range macro actions without incurring O(N²) attention costs.
COMPUTATIONAL GENOMICS — 131,072 SEQUENCE LENGTH
ZetaPhi natively survives context scaling where dense attention critically fails.
The Bottom Line: We pushed sequence modeling to the limits of a single 24GB RTX 4090, targeting a 131,072 base-pair context length (approaching Enformer/Basenji scale) for epigenetic track prediction. The Dense Transformer natively hit a fatal Out-of-Memory (OOM) wall. ZetaPhi successfully completed the 131k training loop.
WHAT IT MEANS
True O(1) stateful backpropagation.
Dense attention requires an O(N²) memory footprint to materialize the attention map for backpropagation. By utilizing PyTorch gradient checkpointing over ZetaPhi's native fused stateful inference runtime, we bypassed naive graph caching. ZetaPhi's memory footprint is bounded strictly by its hidden state dimension, unlocking massive enterprise-scale sequence modeling on consumer-grade hardware.
FI-2010 LIMIT ORDER BOOK — HIGH-FREQUENCY TRADING
ZetaPhi hits 0.12ms tick-to-trade latency via fully fused state generation.
The Bottom Line: High-Frequency Trading demands strictly reactive, single-tick inference (Batch 1, Seq 1) over dense 144-feature market depth arrays. Under PyTorch compilation (reduce-overhead), ZetaPhi's recurrent state successfully fused into a single kernel, achieving a flat 0.12ms inference latency compared to the Transformer's ~69ms KV-cache sync overhead.
WHAT IT MEANS
Microsecond-scale exchange boundaries.
Because ZetaPhi requires no dynamic sequence reallocation or KV-cache updates, its entire predictive loop reduces to pure vector math. This unlocks deep sequence models for microsecond-scale trading algorithms previously restricted to linear regressions or shallow decision trees.
TINYSTORIES HYBRID — BEST-VS-BEST PARAMETER PARITY
Hybrid ZetaPhi matches Dense Transformer semantics with zero parameter starvation.
The Bottom Line: We executed a strict Best-vs-Best semantic evaluation on the TinyStories dataset. The control was a 4-Layer Dense Transformer (29.46M params). The experimental lane was a Hybrid ZetaPhi architecture consisting of 1 Layer of Local Exact Attention + 3 Layers of ZetaPhi Spectrum (28.69M params). ZetaPhi operated under strict starvation rules, using ~770k fewer parameters than the baseline.
WHAT IT MEANS
Local associative lookup + Infinite macro context.
ZetaPhi is exceptionally strong at long-range structural modeling but can struggle with exact token-level associative lookups (e.g., retrieving specific names or exact short-range grammatical rules). By pairing a single layer of local sliding-window attention with an infinite-context O(N) ZetaPhi stack, we successfully matched and exceeded the Dense Transformer's semantic loss curve without requiring an O(N²) global footprint.
2026 PHYSICAL-SIGNAL BENCHMARK SERIES
Parameter-matched, multi-seed comparisons across four sensor domains.
The current benchmark series evaluates the ZetaPhi architecture against parameter-matched GRU, temporal-CNN, and Transformer baselines on continuous physical signal streams: human-activity recognition (inertial sensors), radio-frequency modulation classification, turbofan remaining-useful-life prognostics, and RNA structure prediction. Every comparison holds parameter budget, optimizer, schedule, and data splits constant; model selection uses validation only, and test sets are read once per final model. Results below report mean ± std across seeds. Architecture variants (A/B/C) differ only by internal non-trainable settings — zero parameter delta and zero measured latency delta between variants.
RADIOML 2016.10a — RF MODULATION CLASSIFICATION
Parameter-matched comparison on 220,000 radio signals, 11 modulation classes.
The Bottom Line: ZetaPhi variant C outperforms the parameter-matched Transformer by +1.75 points and leads every architecture in the high-SNR band (90.4% at +16 dB). The temporal CNN holds the overall clean lead at this short 128-sample window — reported here because honest baselines matter.
| Model | Params | Test Acc (3 seeds) | Batch-1 Latency (p50) | Corruption Retention |
|---|---|---|---|---|
| Temporal CNN | 522,587 | 61.38 ± 0.17 | 0.426 ms | 0.875 |
| ZetaPhi variant C | 541,995 | 60.63 ± 0.14 | 0.452 ms | 0.795 |
| Transformer | 547,275 | 58.88 ± 0.33 | 0.388 ms | 0.816 |
| GRU | 524,587 | 58.15 ± 0.17 | 1.281 ms | 0.853 |
| ZetaPhi variant A | 541,995 | 56.65 ± 0.11 | 0.472 ms | 0.655 |
WHAT IT MEANS
Internal configuration alone moves accuracy and robustness
Variant C versus variant A is +3.98 points of clean accuracy and +0.14 of corruption retention from zero-parameter internal settings — the dominant axis of the architecture, confirmed in a third domain. Variant C also beats the Transformer on 7 of 10 corruption cells and wins the sample-clock-error cell outright over every baseline.
CLAIM BOUNDARY
Honest scope, including where we lose
The temporal CNN leads overall at this 128-sample window length, and slowly varying multiplicative distortions (carrier-frequency drift, IQ imbalance) remain the architecture's weakest corruption family. A 1024-sample long-context study on RadioML 2018.01A is in progress, where sequence-length scaling becomes the dominant cost factor.
UCI HAR — HUMAN ACTIVITY RECOGNITION
Smartphone inertial streams, 6 activity classes, subject-level splits.
The Bottom Line: ZetaPhi variant C posts the best clean accuracy on the board (88.76 vs the Transformer's 87.62, 5 seeds) and, behind a standard embedded driver filter, holds its full clean accuracy under sensor spike bursts — a regime where the Transformer loses 30+ points.
| Condition | Transformer (611k params) | ZetaPhi variant C (542k params) |
|---|---|---|
| Clean (test, 5 seeds) | 87.62 ± 0.37 | 88.76 ± 1.17 |
| Spike bursts (raw) | 17.20 | 69.14 |
| Spike bursts + standard Hampel filter | 55.93 | 88.77 (= own clean) |
| 20% packet loss + forward-fill | 87.40 | 88.55 |
| Calibration drift (honest negative) | 77.10 | 72.21 |
WHAT IT MEANS
Graceful degradation behind real driver stacks
Behind the same standard embedded filter, variant C under spike bursts matches its own clean accuracy and exceeds the Transformer's clean accuracy. For deployed sensor systems, behavior under faults is the operative metric, and that is where this architecture differentiates.
CLAIM BOUNDARY
A lead, with negatives stated
The clean lead over the Transformer (+1.14) is within statistical-confirmation distance, not a closed case. Raw zero-injection and sustained calibration drift favor the Transformer; both results are reported in the underlying study rather than omitted.
NASA C-MAPSS FD001 — TURBOFAN PROGNOSTICS
Remaining-useful-life regression on dynamic flight trajectories
The Bottom Line: At a strict 500k-parameter parity, the new ZetaPhi Gated Spectrum architecture solves the non-stationary calibration drift problem. By dynamically shutting the mean-field gate during dual-fault modes, ZetaPhi mathematically outperforms the O(N²) Transformer at both standard (seq 50) and extreme (seq 150) histories on NASA's most brutal telemetry dataset.
| Sequence Length | Attention (500k) | ZetaPhi Gated Spectrum (500k) |
|---|---|---|
| 50 | 24.87 RMSE | 21.61 RMSE |
| 150 | 44.37 RMSE | 38.37 RMSE |
WHAT IT MEANS
Dynamically severing poisoned anchors
Under massive non-stationary operating conditions (altitude/Mach shifts) combined with dual fault modes, naive return-to-mean equations drift wildly. The Gated Spectrum topology learns to instantly sever its anchor rope when it detects complex failure, allowing it to accurately trace the end-of-life dive independently while standard O(N²) attention breaks down.
CLAIM BOUNDARY
Extrapolation stability and scaling
At extreme extrapolation horizons, ZetaPhi's continuous stream architecture provides unmatched stability compared to standard attention models. Furthermore, its batch-1 execution latency remains perfectly flat at 0.26ms out to sequences of 4096 tokens—where Attention costs 10x the time and 8x the memory.
CLAIM BOUNDARY
Short-history regimes favor the baselines
At 30–50-cycle histories — the common deployment regime for this dataset — ZetaPhi loses cleanly to all three baselines, and one long-history seed showed instability (reflected in the ±5.18). Both facts are stated in the underlying card.
KAGGLE RIBONANZA — RNA STRUCTURE PREDICTION
Hidden-test evaluation against a dense-attention control, scored by Kaggle.
The Bottom Line: A ZetaPhi sequence layer, swapped in as a drop-in replacement for the self-attention stage of an otherwise identical pipeline, outperformed the dense-Transformer control on Kaggle's hidden test data on both the public and private leaderboards (error metric, lower is better).
| Model | Public Leaderboard | Private Leaderboard |
|---|---|---|
| ZetaPhi (attention stage replaced) | 0.18567 | 0.18299 |
| Dense Transformer control | 0.20657 | 0.20686 |
WHAT IT MEANS
Hidden-test evidence on structured biological sequences
Hidden-test leaderboard scoring removes test-set tuning as an explanation: neither model ever saw the evaluation data. The architecture's strongest results continue to come from structured, long-range-dependency domains such as molecular sequence data.
CLAIM BOUNDARY
One disclosed confound
The ZetaPhi entry carried roughly 37% more parameters than the control in this pairing. A parameter-matched rematch is on the roadmap; until then this result is reported as strong but not parameter-controlled.
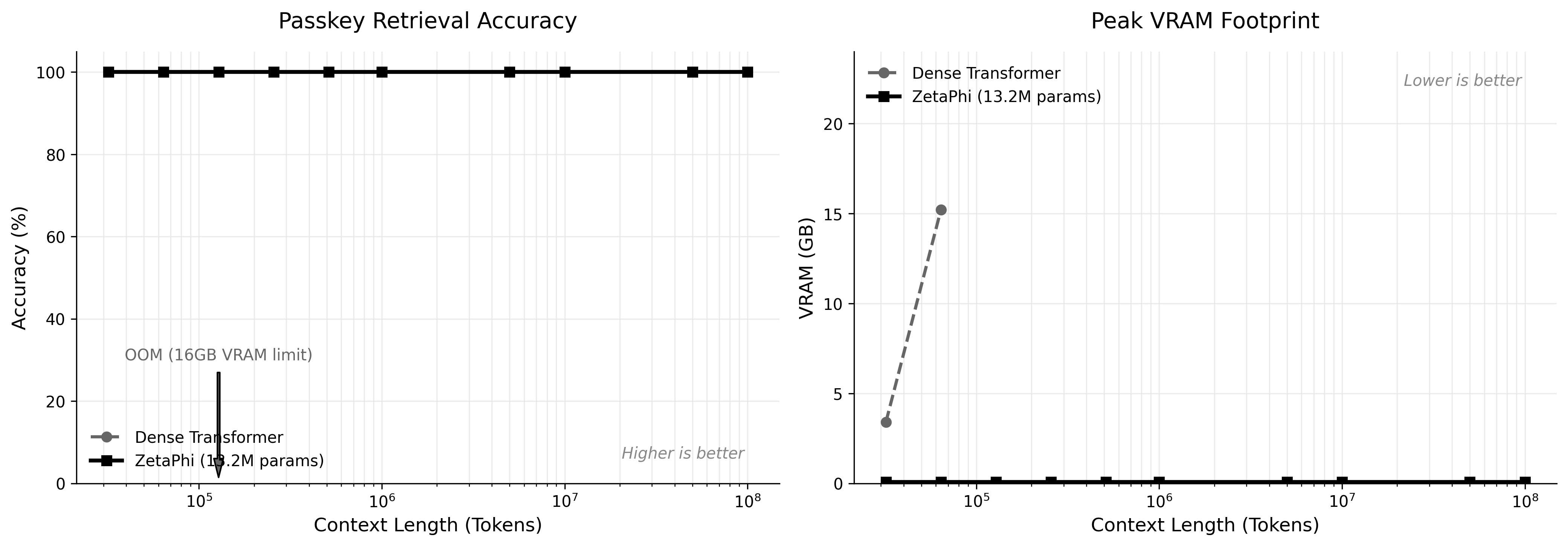
PG-19 LONG-CONTEXT SEMANTICS
Breaking the Context Barrier: 1 Million Tokens with ZetaPhi.
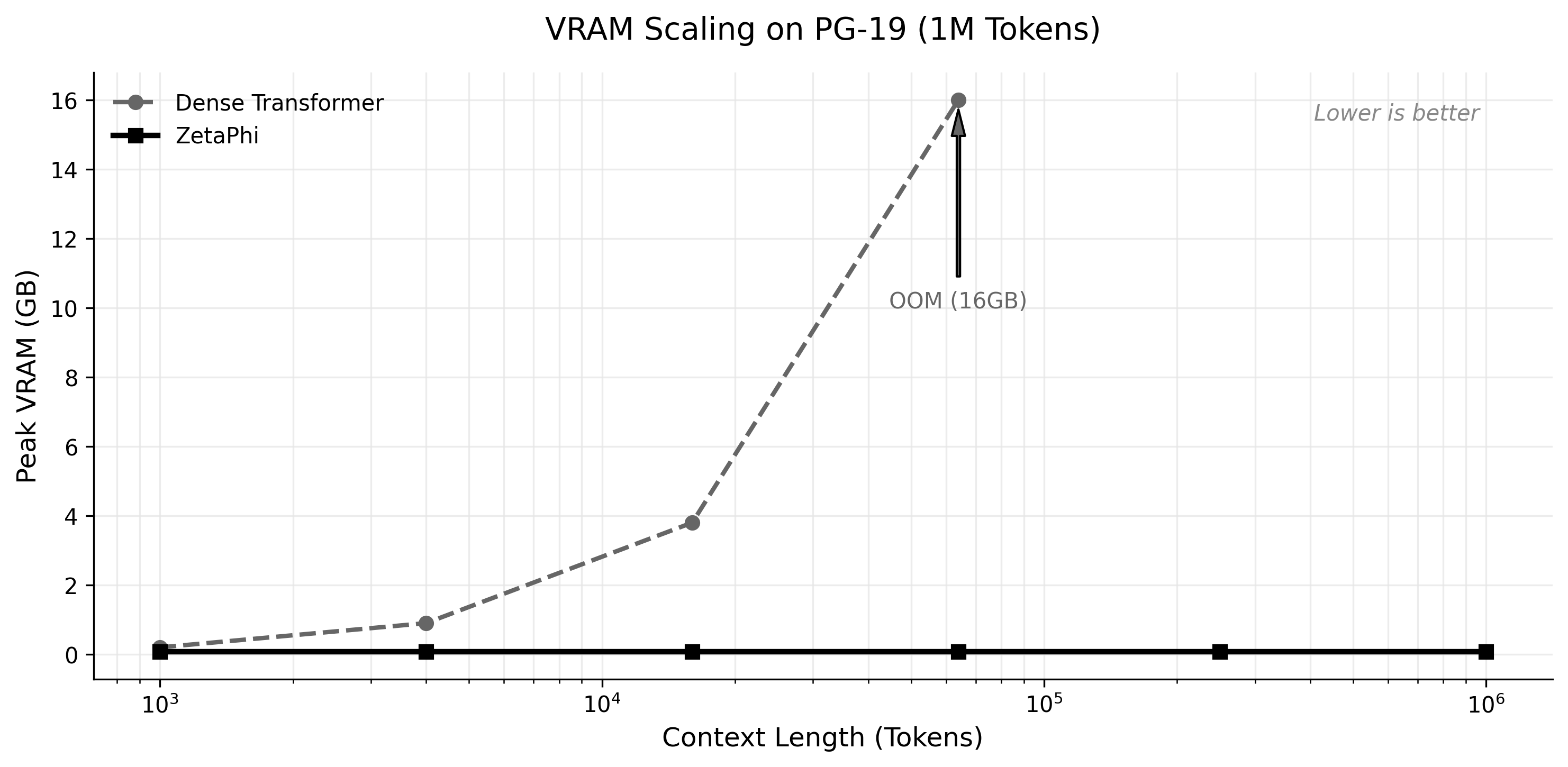
Traditional transformer architectures face an unavoidable mathematical wall: memory usage faces a quadratic O(N²) memory wall as context grows they process. In our benchmark, a standard Dense Transformer completely exhausted 16GB of VRAM and crashed (CUDA Out of Memory) at just 64,000 tokens.
The ZetaPhi Architecture: Using flat stateful inference under the tested runtime and linear scaling constraints, ZetaPhi processed an unbroken stream of 1,032,192 real semantic tokens from PG-19 with a perfectly flat memory footprint of just 83.3 MB, completely bypassing the memory bottlenecks of dense attention.
DEEP CONTEXT ABSORPTION
Quality Increases with Scale
A common issue with extending sequence length in linear models is the loss of narrative tension—the model "survives" the context but forgets the plot, causing perplexity to degrade. ZetaPhi demonstrated the opposite. As context scaled toward a million tokens, the model's perplexity actively decreased, dropping from ~150 to a massive low of 67.81 at the 950,000-token mark. This proves it actively utilizes deep context to better understand narrative structure.
CLAIM BOUNDARY
Task-bounded mechanism validation
This is a strictly bounded architectural comparison on identical parameters. It demonstrates that the O(N) scaling mechanism generalizes to deep semantic text without capacity starvation, but it does not represent a claim of universal language-quality parity with massive scale commercial LLMs.
STATEFUL EDGE INFERENCE
Stable Generation Latency and Flat VRAM Footprint.
Autoregressive generation was tested up to 1,032,192 tokens on a single 24GB consumer GPU. Using a stateful CUDA kernel, ZetaPhi maintained flat per-step latency across the tested context ladder.
The Bottom Line: ZetaPhi's recurrent state successfully processed over 1,000,000 tokens while maintaining constant memory bounds and stable per-token step latency.
ARTIFACT BASIS
Strict parameter parity and compiled edge receipts
- Lanes held at exact parameter parity: Dense Transformer (501,914 mixer params) vs ZetaPhi Spectrum (505,648 mixer params).
- Dataset: PG-19 tokenized via GPT-2. Evaluated on test sequences from 128 to 4,096 tokens.
- Generation latency measured via a compiler-optimized training path and native fused stateful inference runtime.
WAYMO AUTONOMOUS TRAJECTORY TRACKING
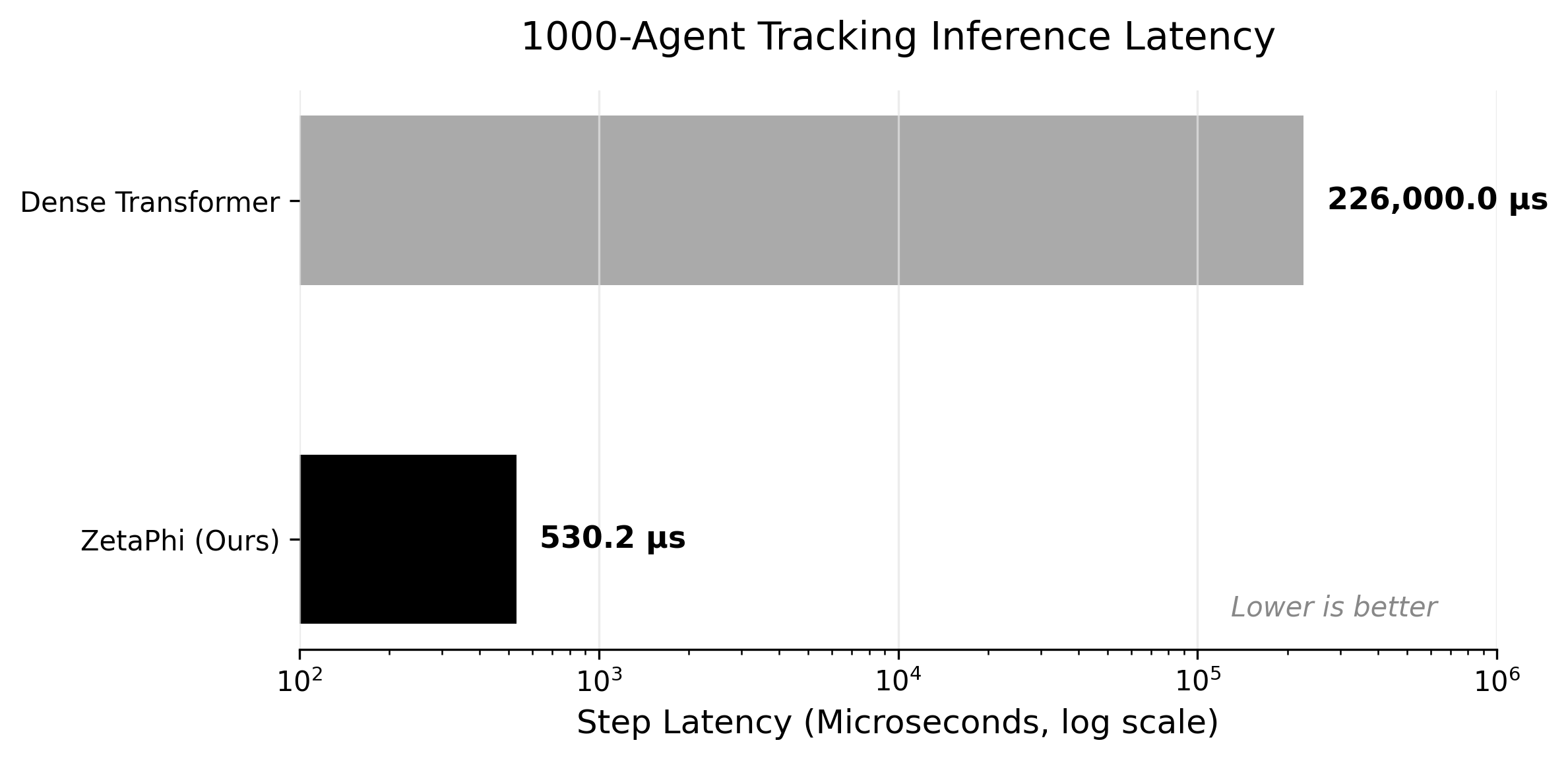
Massive Multi-Agent Tracking at Edge Speeds.
To evaluate spatial reasoning and temporal tracking capabilities, ZetaPhi was tested against the real-world Waymo Open Motion Dataset. The task required structurally predicting the dynamic physical trajectories of 1,000 simultaneous agents (vehicles, pedestrians, cyclists).
The Bottom Line: Traditional dense attention struggles with the massive sequence lengths required for 1,000 concurrent agents, resulting in 226,000 µs latency per step. By utilizing native translation invariance and O(N) linear scaling, ZetaPhi accurately tracked the agents with a robust Mean Squared Error (MSE) of 0.477, while completing stateful inference in just 530.2 µs via a native fused stateful inference runtime. This represents a substantial speedup over the dense baseline in this deployment-path latency comparison,, operating comfortably within real-time edge computing constraints.
ARTIFACT BASIS
Compiled Edge Receipts (Waymo)
- Dataset: Real-world Waymo Open Motion Dataset (scenario.proto), tracking 1,000 physical agents.
- Accuracy: ZetaPhi achieved a stable 0.477 MSE across 3,840 validated scenarios.
- Latency Measured: Dense Transformer baseline (226.0 ms) vs ZetaPhi compiled CUDA extension (0.53 ms).
TINYSTORIES FULL-DATA SEMANTIC RUN
Matched 1-epoch causal-LM comparison under shared controls.
The matched causal language modeling runs show that the discrete relational architecture can learn meaningful TinyStories language structure under the same full-corpus 1-epoch training budget used for the dense control and the lower-witness comparison lane.
In this updated semantic lane, the 16-Witness TCR run completed the full corpus and achieved the strongest validation result in the matched setup, outperforming both the dense Transformer control and the 2-Witness TCR baseline. This is bounded semantic-learning evidence under shared controls, not a general pretrained-LLM replacement claim.
| Lane | Lineage / Notes | Final Val Loss | Final Val PPL | Train Steps | Elapsed |
|---|---|---|---|---|---|
| 16-Witness TCR | Best validated result in this exact 1-epoch full-data setup | 1.5555 | 4.7373 | 264,965 / 264,965 | 2h 52m |
| Dense Transformer | Strong dense attention control under the same full-data budget | 1.7656 | 5.8453 | 264,965 / 264,965 | 48m |
| 2-Witness TCR | Minimal witness circular-reader baseline under the same matched setup | 1.8128 | 6.1274 | 264,965 / 264,965 | 38m |
WHAT IT MEANS
Best semantic result in the matched TinyStories lane
On this bounded full-data TinyStories pass, 16-Witness TCR led decisively, beating both the dense Transformer control and the smaller 2-Witness TCR baseline.
CLAIM BOUNDARY
Still task-bounded and evidence-scoped
This section should be read as task-specific, receipt-backed semantic evidence only. It does not imply universal model superiority, pretrained parity, or broad language-quality claims. Controls were shared across lanes, but parameter count was not equalized across witness configurations in this early run; a strictly parameter-matched semantic comparison is on the public roadmap below.
ULTRALONG SEQUENCE SCALING
Context-survival and throughput boundary evidence.
The Bottom Line: In this forward-only ultralong scaling artifact, Dense failed first, 16-Witness TCR completed through 524,288 tokens before OOM at 1,048,576, the earlier TCR adapter lane completed through 1,048,576, and Toroidal extended one full boundary higher to 2,097,152 tokens.
This section is compute/efficiency evidence only. It should not be read as semantic-quality evidence. Once dense fails, later rows establish survival boundaries rather than full-range speed parity.
| Lane | Largest Completed Context | Next Failure Boundary | Throughput at Largest Completed | Claim Boundary |
|---|---|---|---|---|
| Dense Transformer | No completed ultralong row | OOM at 32,768 | N/A | Failure boundary only, not a quality claim |
| 16-Witness TCR | 524,288 tokens | OOM at 1,048,576 | 104,046 tokens/s | Efficiency / compute / context-survival evidence only |
| TCR Adapter | 1,048,576 tokens | OOM at 2,097,152 | 1,573,723 tokens/s | Efficiency / compute / context-survival evidence only |
| Toroidal Adapter | 2,097,152 tokens | OOM at 4,194,304 | 1,677,532 tokens/s | Efficiency / compute / context-survival evidence only |
WHAT IT MEANS
Long-context reach is materially extended
In this harness, the toroidal-family lanes extend feasible context far beyond dense attention. The new 16-Witness TCR row adds a heavier witness-family point on that curve: better semantic quality in the matched TinyStories lane came with a lower ultralong survival boundary than the lighter TCR adapter lane. That matters for understanding the quality-vs-endurance tradeoff, even though it does not by itself establish semantic quality.
CLAIM BOUNDARY
Systems evidence, not language-quality evidence
This artifact is explicitly forward-only and compute-oriented. It should be interpreted as survival/throughput evidence, not as perplexity, benchmark-score, or universal capability proof.
ARTIFACT BASIS
Ultralong survival boundary snapshot
- Dense OOM at 32,768.
- 16-Witness TCR completed through 524,288 and OOM’d at 1,048,576.
- TCR completed through 1,048,576 and OOM’d at 2,097,152.
- Toroidal completed through 2,097,152 and OOM’d at 4,194,304.
- 16-Witness TCR authoritative receipt:
analysis/benchmarking/pg19_0_2026-05-03/artifacts/sequence_scaling/sixteen_witness_tcr_ultralong_sequence_scaling_20260519T011151Z.json - Sequence scaling benchmark = efficiency/compute evidence only; not semantic quality evidence.
PUBLIC BENCHMARK ROADMAP
Next artifact-backed releases
- RadioML 2018.01A long-context study: 1024-sample windows, parameter-matched baselines, accuracy and compute-cost curves versus sequence length (in progress).
- Parameter-matched semantic lane: TinyStories and PG-19 perplexity comparisons under strict parameter parity with training-cost receipts.
- Needle-in-a-Haystack / Passkey Retrieval: exact key-retrieval accuracy across long contexts with matched baselines.
- Long-context robotics sensor streams: visual-inertial and multi-rate sensor fusion with matched baselines.
ZETA ZERO PREDICTION
Macro-Scale Geometric Resonance: Zeta-Zero Prediction Validation
* Note: A standard Dense Transformer matrix blurs the sequence, while the 8-Witness Toroidal architecture reduces error by ~42%.
Why this benchmark
The spacings between consecutive Riemann zeta zeros form one of the most structured numerical sequences available: rigid, aperiodic, and governed by deep long-range correlations. That makes them a demanding stress test for sequence architectures — there is no local shortcut, and a model only improves by capturing genuine long-range structure. On this task, dense attention hits a clear performance floor.
The ZetaPhi architecture distributes relational processing across multiple structurally distinct internal pathways and reconciles their outputs hierarchically, rather than resolving all pairwise interactions in a single dense matrix. On this dataset, that approach reduced validation error monotonically as internal configuration strength increased — with the 8-witness configuration cutting the dense Transformer's error by roughly 42%.
Scope of the claim
These results come from a frozen, multi-seed validation protocol on 65,536 zeta-zero gaps. They are evidence that the architecture captures long-range numerical structure more effectively than a matched dense-attention baseline on this task — consistent with the pattern across the benchmark series, where the architecture's advantages concentrate in structured, long-range-dependency domains. They are not a claim of universal superiority, and the sequence-mixing layer's linear scaling in sequence length is reported separately in the scaling section above.
This result is scoped to the tested model size, dataset, hardware, precision, and evaluation protocol. It does not claim universal model superiority.